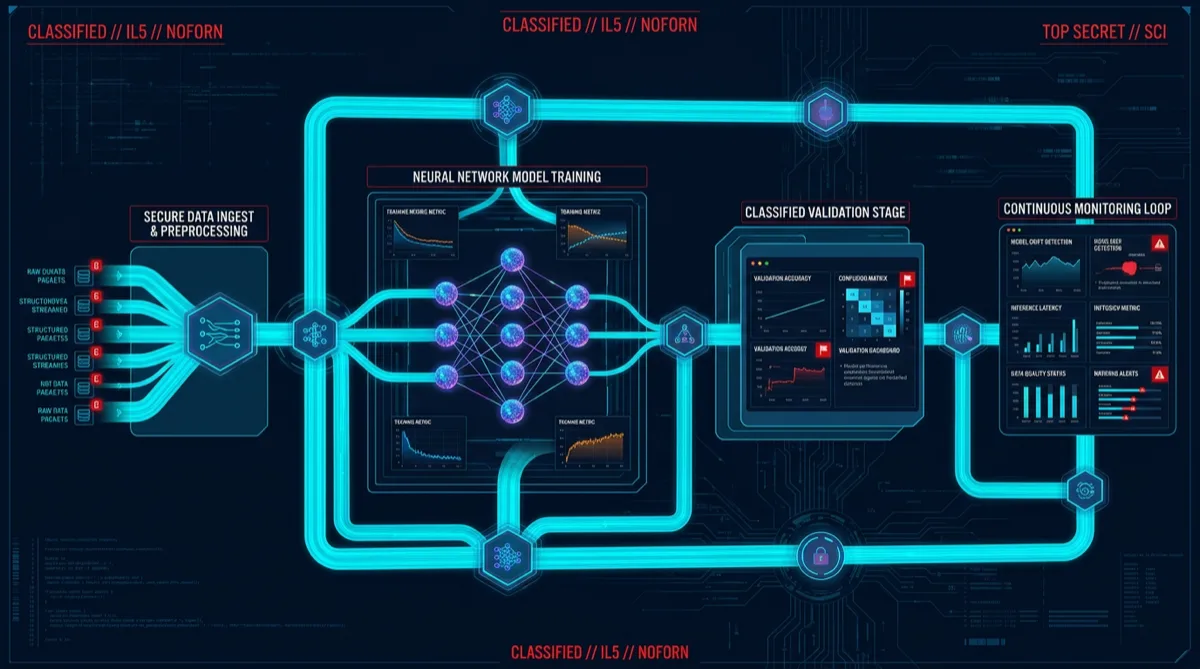
Machine learning operations in classified environments carry constraints that civilian MLOps practitioners rarely encounter: data that can't leave a specific IL boundary, models that require chain-of-custody documentation, and inference infrastructure that must satisfy ATO controls alongside ML-specific tooling requirements.
This covers the MLOps architecture patterns Rutagon applies for defense and intelligence-adjacent programs operating at Impact Level 5 on AWS GovCloud.
The IL5 MLOps Constraint Set
IL5 authorizes National Security Systems (NSS) workloads — Controlled Unclassified Information at the higher end of the CUI spectrum and unclassified NSS data. AWS GovCloud regions (us-gov-west-1, us-gov-east-1) are the standard platform for IL5 workloads, with additional controls required beyond the standard AWS GovCloud baseline.
For an MLOps pipeline, IL5 imposes constraints across several dimensions:
Data access: Training data must remain within the IL5 authorization boundary. External dataset pulls (HuggingFace, public S3 buckets, external APIs) require explicit authorization. Most programs use curated training datasets within S3 buckets in the same GovCloud account.
Internet egress: IL5 systems typically implement strict egress controls. Pre-trained model weights from public registries (HuggingFace Hub, PyPI ML packages) must be vendored into the boundary or pulled through an authorized proxy — not directly from the internet during pipeline execution.
Model artifact chain of custody: The model — from training run to production inference endpoint — must have auditable provenance. Who trained it, what data, what hyperparameters, and what validation results are compliance-relevant artifacts, not just engineering records.
Inference endpoints: ML inference services are subject to the same ATO controls as any other GovCloud application — NIST 800-53 controls, ConMon integration, boundary documentation. The model container is an additional artifact requiring scanning and signing.
Training Pipeline Architecture on GovCloud
Rutagon's baseline IL5 ML training pipeline runs on Amazon SageMaker within the GovCloud boundary (SageMaker is available in us-gov-west-1):
Data Source (S3, GovCloud)
│
▼
SageMaker Processing Job
(feature engineering, data validation)
│
▼
SageMaker Training Job
(custom training container from ECR Private — Iron Bank base image)
│
▼
Model artifact → S3 (versioned, encrypted with KMS CMK)
│
▼
SageMaker Model Registry
(approval workflow — manual gate before production promotion)
│
▼
SageMaker Endpoint (inference, VPC-bound, no public endpoint)Container provenance: Training containers are built from Iron Bank base images where available, or from approved GovCloud ECR images with documented ancestry. All containers are scanned with Trivy and signed with AWS Signer before use. Container SHA digests are recorded in the model registry entry.
Data lineage: SageMaker Pipelines captures dataset version, feature engineering parameters, and training script version as pipeline metadata. This metadata constitutes the training data chain-of-custody record.
KMS encryption: Training data (S3), model artifacts (S3), and endpoint storage are all encrypted with KMS Customer Managed Keys (CMKs) with documented key policies. CMK rotation is enabled. Key usage is logged in CloudTrail.
Model Validation and Approval Gates
Moving from trained model to production inference requires a defined validation and approval workflow. This is where most civilian MLOps patterns fall short for compliance programs.
Rutagon implements a three-gate validation pipeline:
Gate 1 — Technical validation: Automated tests against a held-out validation dataset. Minimum performance thresholds (accuracy, F1, or domain-appropriate metric) must be met before the model proceeds. Failing models are archived but not promoted.
Gate 2 — Security review: Model artifacts are scanned for adversarial manipulation indicators (model inversion risk, backdoor patterns relevant to the domain). For programs using externally provided pre-trained weights (fine-tuned foundation models), this gate includes documentation of the source weights' authorization status.
Gate 3 — Manual approval: A named program technical authority (or authorized designee) approves production promotion in the SageMaker Model Registry. This creates a human signature in the audit trail — important for programs where model decisions have operational consequences.
The approval workflow generates an artifact (approval record with approver identity, timestamp, and model SHA) that becomes part of the ATO evidence package.
Inference Infrastructure Controls
SageMaker inference endpoints at IL5 require additional configuration beyond default:
VPC isolation: Endpoints run in a dedicated VPC with no public endpoint. Consumers access the endpoint through a VPC endpoint or internal application load balancer.
Resource-based policy: Endpoint invocation is restricted to specific IAM principals — the inference application service accounts, not any IAM identity in the account.
Inference logging: Every prediction request is logged — not the prediction itself necessarily, but the requester identity, timestamp, and request hash. This supports incident investigation if anomalous inference patterns are detected.
Auto-scaling bounds: Inference endpoints are bounded with minimum and maximum instance counts to prevent resource-based DoS conditions. Scaling events are logged to CloudWatch and feed the ConMon dashboard.
ConMon Integration for ML Systems
The continuous monitoring challenge for ML systems: model drift (accuracy degradation over time as data distributions shift) is a security-relevant event in addition to an ML quality issue. A model whose accuracy degrades significantly may produce outputs that downstream systems rely on incorrectly.
Rutagon's ConMon integration for ML systems includes:
Model performance metrics → CloudWatch: Key inference metrics (prediction distribution, confidence score distribution, latency) are published to CloudWatch and trigger alarms when they deviate from trained behavior baselines.
SageMaker Model Monitor: Periodic evaluation jobs run against production inference data to detect data drift and model quality drift. Drift alerts feed the ConMon dashboard.
ATO re-review triggers: The program documents thresholds at which significant model drift triggers an ATO re-review — the model's accuracy profile is part of the system's security posture documentation.
Defense programs with ML/AI workloads needing IL5-compliant MLOps pipelines can contact Rutagon at contact@rutagon.com.
Related: Managed DevSecOps Pipeline for Prime Delivery | Continuous Monitoring NIST RMF | CUI Cloud Enclave on GovCloud
Frequently Asked Questions
Can AWS SageMaker be used for classified ML workloads?
AWS SageMaker is available in AWS GovCloud (us-gov-west-1) and is authorized at FedRAMP High. SageMaker's availability for IL5 NSS workloads depends on the specific AO's system boundary documentation. For programs at IL5, SageMaker is typically evaluated alongside the full ATO package for the GovCloud account. Rutagon has experience documenting SageMaker components within IL5 ATO boundaries.
How do you handle pre-trained model weights in an IL5 environment?
Pre-trained weights from public sources (HuggingFace, PyPI, GitHub) require authorization before entering the IL5 boundary. This typically involves reviewing the model's training data provenance, licensing, and export control applicability. Approved weights are imported through an authorized scanning pipeline (malware scan, integrity verification) and stored in the boundary's approved artifact registry before use in training or fine-tuning jobs.
What is model chain of custody in federal ML programs?
Model chain of custody is the documented record of: what data was used to train the model, what training parameters and script version produced it, what validation results it achieved, who approved it for production, and what inference configuration it operates under. This documentation is part of the ATO evidence package for systems that include ML inference as a component.
How does model drift affect an IL5 ATO?
Model drift — accuracy or behavioral degradation over time — can affect the security posture of systems that rely on ML inference for security-relevant decisions. Most IL5 ATO packages document the expected operating envelope for model performance and specify re-authorization triggers if performance degrades beyond defined thresholds. Rutagon implements SageMaker Model Monitor to detect drift and alert the program ConMon team.
What's different about MLOps in defense vs commercial environments?
Key differences: data cannot leave a defined classification boundary (no external API calls for public datasets during training runs), model artifacts require chain-of-custody documentation matching NIST control evidence standards, inference endpoints are subject to full ATO controls rather than just operational SLAs, and model approval workflows require named human approvers rather than fully automated CI/CD promotion.