# Event-Driven Architecture on AWS for Production Systems
Event-driven architecture on AWS is how we build systems that scale without becoming fragile. After shipping production platforms that orchestrate 24+ Lambda functions across dozens of event sources, we've learned that the difference between a demo and a production event-driven system comes down to how you handle failure — not how you handle success.
This isn't a theoretical overview. These are the patterns we use when building real systems that process thousands of events daily across regulated and commercial environments.
Why Event-Driven Architecture Matters in Production
Request-response architectures couple services together. When Service A calls Service B synchronously, A has to wait. If B is slow, A is slow. If B is down, A might be down. Multiply this across a dozen services and you've built a distributed monolith.
Event-driven architecture inverts this. Services publish events. Other services react to those events asynchronously. The publisher doesn't know or care who's listening. This decoupling is what makes systems resilient at scale.
In our production SaaS platform — which spans iOS, Android, and web clients backed by 25+ AWS services — event-driven patterns are the backbone. User actions trigger Lambda functions via API Gateway. Those functions publish events that cascade through processing pipelines. Each stage is independent, retryable, and observable.
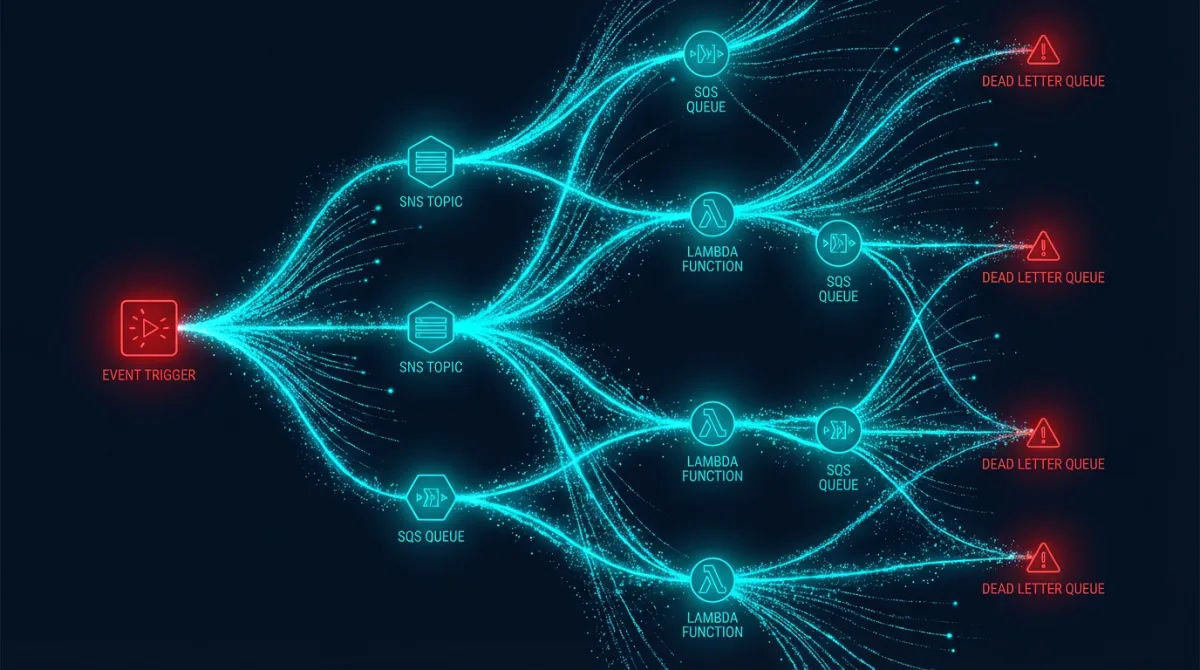
The AWS Event-Driven Toolkit
AWS gives you three primary building blocks for event-driven systems, and knowing when to use each is critical.
SNS: Fan-Out Messaging
Amazon SNS is a pub/sub service. A producer publishes a message to a topic, and all subscribers receive it. Use SNS when one event needs to trigger multiple independent consumers.
# CloudFormation: SNS topic with SQS subscriptions for fan-out
OrderCompletedTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: order-completed
KmsMasterKeyId: alias/sns-encryption
InventoryQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: inventory-processing
RedrivePolicy:
deadLetterTargetArn: !GetAtt InventoryDLQ.Arn
maxReceiveCount: 3
NotificationQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: notification-processing
RedrivePolicy:
deadLetterTargetArn: !GetAtt NotificationDLQ.Arn
maxReceiveCount: 3An order completion event fans out to inventory, notifications, analytics, and billing — each processing independently through their own SQS queues.
SQS: Reliable Queuing
SQS is the workhorse. It guarantees at-least-once delivery, handles backpressure naturally, and pairs perfectly with Lambda as a trigger. Standard queues give you near-unlimited throughput. FIFO queues give you ordering guarantees when you need them.
The critical configuration most teams miss is the visibility timeout. If your Lambda function takes 60 seconds to process a message but your visibility timeout is 30 seconds, SQS will hand that message to another consumer mid-processing — creating duplicate work and potential data corruption.
import json
import hashlib
import boto3
dynamodb = boto3.resource('dynamodb')
idempotency_table = dynamodb.Table('idempotency-keys')
def handler(event, context):
for record in event['Records']:
body = json.loads(record['body'])
idempotency_key = compute_idempotency_key(body)
try:
idempotency_table.put_item(
Item={
'idempotency_key': idempotency_key,
'processed_at': context.get_remaining_time_in_millis(),
'ttl': int(time.time()) + 86400
},
ConditionExpression='attribute_not_exists(idempotency_key)'
)
except dynamodb.meta.client.exceptions.ConditionalCheckFailedException:
print(f"Duplicate event detected: {idempotency_key}")
continue
process_event(body)
def compute_idempotency_key(event_body):
canonical = json.dumps(event_body, sort_keys=True)
return hashlib.sha256(canonical.encode()).hexdigest()EventBridge: Event Routing at Scale
EventBridge is the most powerful and least understood of the three. It's a serverless event bus with content-based routing. You define rules that match event patterns and route them to targets — Lambda, SQS, Step Functions, API destinations, and more.
Where EventBridge shines is cross-account and cross-service event routing. In a multi-account AWS Organization (which is how we structure every production environment), EventBridge lets you route events from workload accounts to a central observability account without direct service coupling.
{
"source": ["com.platform.orders"],
"detail-type": ["OrderCompleted"],
"detail": {
"total": [{ "numeric": [">=", 1000] }],
"region": ["us-gov-west-1", "us-gov-east-1"]
}
}This rule only fires for high-value orders in GovCloud regions. That kind of content-based filtering keeps your consumers focused on events they actually need.
Dead Letter Queues: Where Failures Go to Be Fixed
Every SQS queue in production needs a dead letter queue (DLQ). Every one. A DLQ catches messages that failed processing after a configured number of retries. Without one, poison messages cycle endlessly, burning Lambda invocations and masking the real problem.
But setting up a DLQ is only half the battle. You need a process for draining it. We build DLQ processors that:
- Alert when messages land in the DLQ (CloudWatch alarm on ApproximateNumberOfMessagesVisible)
- Provide visibility into failure reasons via structured logging
- Support replaying messages back to the source queue after the bug is fixed
import { SQSClient, ReceiveMessageCommand, SendMessageCommand, DeleteMessageCommand } from '@aws-sdk/client-sqs';
const sqs = new SQSClient({});
export async function replayDLQ(dlqUrl: string, sourceQueueUrl: string): Promise<number> {
let replayed = 0;
while (true) {
const response = await sqs.send(new ReceiveMessageCommand({
QueueUrl: dlqUrl,
MaxNumberOfMessages: 10,
WaitTimeSeconds: 1,
}));
if (!response.Messages || response.Messages.length === 0) break;
for (const message of response.Messages) {
await sqs.send(new SendMessageCommand({
QueueUrl: sourceQueueUrl,
MessageBody: message.Body!,
MessageAttributes: message.MessageAttributes,
}));
await sqs.send(new DeleteMessageCommand({
QueueUrl: dlqUrl,
ReceiptHandle: message.ReceiptHandle!,
}));
replayed++;
}
}
return replayed;
}Retry Patterns That Don't Cascade
The default SQS-Lambda retry behavior is aggressive — failed messages retry immediately. In production, this is dangerous. If a downstream service is down, immediate retries amplify the problem.
Configure exponential backoff through visibility timeout manipulation or use Step Functions for orchestrated retries with configurable delays. For critical workflows, Step Functions give you explicit retry configuration:
ProcessOrder:
Type: Task
Resource: !GetAtt ProcessOrderFunction.Arn
Retry:
- ErrorEquals: ["TransientError"]
IntervalSeconds: 5
MaxAttempts: 3
BackoffRate: 2.0
- ErrorEquals: ["States.TaskFailed"]
IntervalSeconds: 30
MaxAttempts: 2
BackoffRate: 1.5
Catch:
- ErrorEquals: ["States.ALL"]
Next: HandleFailureThis gives you five seconds, then ten, then twenty for transient errors — with a separate, slower retry path for unexpected failures.
Idempotency Is Non-Negotiable
At-least-once delivery means your consumers will occasionally process the same event twice. This is a guarantee, not an edge case. Every event handler must be idempotent.
We use DynamoDB-backed idempotency keys with TTLs. The pattern is straightforward: hash the event payload, attempt a conditional write to the idempotency table, and skip processing if the key already exists. The TTL ensures the table doesn't grow unbounded.
For Lambda functions, the Powertools for AWS Lambda library provides an idempotency decorator that handles this automatically with DynamoDB. We use it extensively in production.
Event Schema Evolution
The hardest problem in event-driven systems isn't delivery — it's schema evolution. When Event V1 adds a new required field to become Event V2, every consumer must handle both versions during the transition.
EventBridge Schema Registry helps here. It discovers and stores event schemas automatically, generates code bindings, and tracks schema versions. Pair this with a deployment strategy where consumers are updated before producers, and you can evolve schemas without breaking existing flows.
Production Lessons from Real Systems
Building a serverless API with Lambda and DynamoDB is where most teams start. But production event-driven systems require additional patterns that only emerge under real load:
Batch processing with SQS: Configure BatchSize and MaximumBatchingWindowSeconds on your Lambda event source mapping. Processing 10 messages per invocation instead of 1 dramatically reduces cost and cold start overhead.
Partial batch failure reporting: Enable FunctionResponseTypes: ["ReportBatchItemFailures"] so that only failed messages in a batch return to the queue — not the entire batch.
Event ordering: When ordering matters (financial transactions, state machines), use SQS FIFO queues with message group IDs. But understand the throughput trade-off: 300 messages/second per group ID versus near-unlimited with standard queues.
Investing in real-time data dashboards for your event flows provides the visibility you need to catch problems before they cascade. We build dashboards that track event throughput, processing latency, DLQ depth, and consumer lag across every pipeline.
Our approach to AWS cloud infrastructure treats event-driven patterns as a core architectural primitive — not an afterthought bolted onto a request-response system.
Frequently Asked Questions
What's the difference between SNS, SQS, and EventBridge?
SNS is pub/sub fan-out — one message to many subscribers. SQS is point-to-point queuing — reliable message delivery with backpressure. EventBridge is an event bus with content-based routing and native integrations across AWS services and third-party SaaS. In practice, you combine all three: EventBridge for routing, SNS for fan-out, and SQS for reliable consumption with Lambda.
How do you handle duplicate events in an event-driven system?
Every consumer must be idempotent. We use DynamoDB conditional writes with a hash of the event payload as the idempotency key. If the key already exists, the event was already processed and we skip it. TTLs on the idempotency records prevent unbounded table growth. The Powertools for AWS Lambda library automates this pattern.
When should you use SQS FIFO queues vs. standard queues?
Use FIFO queues only when message ordering within a logical group is required — financial transactions, state machine transitions, or sequential workflow steps. Standard queues offer dramatically higher throughput and lower cost. Most event-driven workloads don't actually need strict ordering; they need idempotency.
How do you monitor event-driven systems in production?
Three things: CloudWatch alarms on DLQ depth (any message in a DLQ is a production issue), distributed tracing with X-Ray correlation IDs propagated through event payloads, and structured logging with consistent event IDs across all consumers. Dashboard everything and alert aggressively on DLQ growth.
What's the biggest mistake teams make with event-driven architecture?
Not planning for failure from day one. Teams build the happy path — events flow, consumers process, everything works. Then a downstream service goes down and messages pile up, retries cascade, and the DLQ overflows because nobody built a replay mechanism. Design your failure handling before you write your first event handler.
---
Building event-driven systems that actually work in production requires more than wiring up SNS topics. Talk to Rutagon about designing resilient, scalable event architectures on AWS.